下面是运行结果,速度比查表快,占用空间比查表小,测试环境是x86_64 mingw-w64 GCC 11.4,-O1 优化

原理剖析:
假设我们要计算一个crc8,多项式为0x11。我们对它使用查表法一次计算4位,那他的函数可以写成
unsigned char crc_table[16]=
{
0x00,0x11,0x22,0x33,
0x44,0x55,0x66,0x77,
0x88,0x99,0xAA,0xBB,
0xCC,0xDD,0xEE,0xFF
};
unsigned char mycrc(unsigned char *data,unsigned int length)
{
unsigned char crc=0;
while(length--){
//第一次查表
crc=crc_table[(crc>>4)^(data[0]>>4)]^crc<<4;
//第二次查表
crc=crc_table[(crc>>4)^(data[0]&0x0F)]^crc<<4;
}
}
我们可以看到,因为并行位数选取和多项式的特殊导致我们的表的数据十分有规律,表的元素和他的索引值有关,索引是0xF,对应元素就是0xFF,索引是0x4,对应元素就是0x44。我们完全可以用索引值经过位运算得到索引对应的值,比如这个函数的并行值是4,表的索引值就等于crc的前4位异或上新的4位数据,得到索引值index后对应值就是(index<<4|index)。
我们就可以将函数改写为
unsigned char mycrc_new(unsigned char *data,unsigned int length)
{
unsigned char crc=0;
unsigned char temp;
while(length--){
temp=(crc>>4^(*data>>4));
temp=temp<<4|temp;
crc=(crc<<4)^temp;
temp=(crc>>4^(*data&0x0F));
temp=temp<<4|temp;
crc=(crc<<4)^temp;
data++;
}
return crc;
}
由于输入数据的宽度是8位,但一次计算只能计算4位,所以我们将循环展开了一次,一次迭代两次运算,但是我们还可以通过位运算直接将两次合并在一起,下面是推导示例,一个小白框就是4位数据。

现在我们只需要按照结果写出代码就好了
unsigned char mycrc_new1(unsigned char *data,unsigned int length)
{
unsigned char crc=0;
while(length--){
crc^=crc>>4;
crc^=(*data)>>4;
crc^=(*data);
crc^=crc<<4;
data++;
}
return crc;
}
我们一直都在讨论多项式为0x44,并行4位的计算方法,我们是通过“表的元素和他的索引值有关”性质推导得到计算方法。
我们将他一般化。这个性质是由多项式决定,并行度也是多项式决定,如果将多项式以二进制的形式展开后,只要多项式中所有两个二进制1之间都存在0就有这个性质,比如多项式crc16-ccitt的多项式是0x1021,他就有这个性质。而多项式0x04C11DB7就不行。
其次是一次可以并行计算多少位,这取决于多项式中两个1之间的最小间隔的0的个数(首位忽略掉的1不算),比如0x44,最小间隔3个0,可以一次并行计算3+1位。又比如0x1021,最小间隔4个0,可以一次并行计算4+1位。
我们以常用的crc16-ccitt为例(下面的代码是xmodem的,但是网上一堆把xmodem当ccitt的,还有把ccitt-false当ccitt的,就这样吧),他的无表并行就可以这么写。
unsigned short crc16_ccitt(unsigned char *data, unsigned int length)
{
unsigned short crc = 0;
while (length--)
{
unsigned char data_in = *data++;
unsigned char data_out = crc >> 8;
crc <<= 8;
data_out ^= (data_out >> 4);
data_out ^= (data_in >> 4);
unsigned short xorred = data_out ^ data_in;
crc ^= xorred;
crc ^= xorred <<5;
crc ^= xorred <<12;
}
return crc;
}
由于这个方法受限于多项式的形式,我们需要观察多项式后才能知道能不能用无表并行方法,当然这只是受限于普通的单通道CRC计算。
在存储器领域存在多通道CRC计算,我们以SDIO的4bit传输模式为例:

我们可以看到SDIO在4bit传输模式下,每条通道都有一个crc16校验码,而且这个校验码的计算方式并不是,
第一组n/4个数据的CRC16在第三通道,
第二组n/4个数据的CRC16在第二通道,
第三组n/4个数据的CRC16在第一通道,
第四组n/4个数据的CRC16在第零通道,
(n是SD卡传输时1个数据块(称之为扇区好理解一点)含有的字节数,通常是512及其倍数,)
而是通道发送的数据的crc16,比如通道3的crc是由每个字节的b7,b3组成的数据计算来的,通道1的crc是由每个字节的b5,b1组成的数据计算来的。对于这种映射关系的多通道CRC校验码计算,我们可以将多通道CRC校验码计算转化为单通道CRC校验码计算。
下面是推导方法

我们还可以将这种映射关系的多通道CRC校验码转化为单通道CRC校验码方法一般化

我们花费如此多的篇幅有什么意义呢,因为多通道转单通道的多项式一定会补0,所以多通道转成的单通道的多项式一定可以无表并行计算。
下面是github上的开源项目pico-sdio-example用于计算SD卡在4bit传输模式CRC的函数,一次计算32位数据
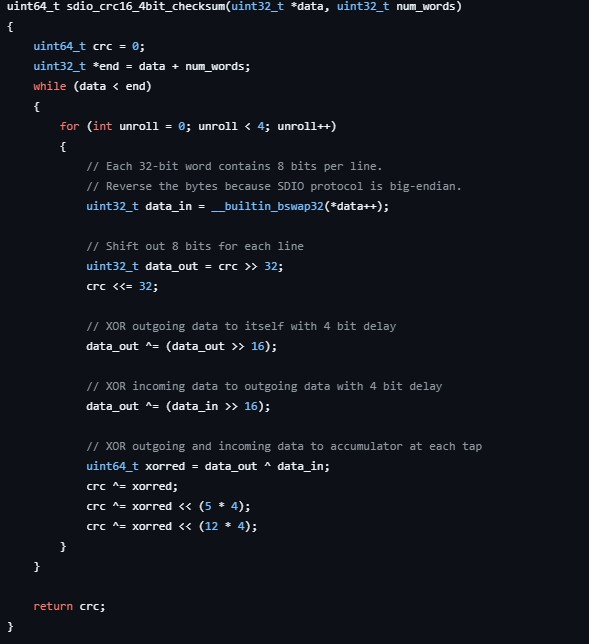
sdio_crc16_4bit_checksum函数原理推导

再左脚踩右脚一下,推导一次计算64位的方法

效果不大,只是32位展开了一次循环而已。没有从并行16位推导到并行32位的速度是3.9倍的提升大,自己展开循环,水平不到位肯定是比不上编译器的,继续推导意义不大。

当然SDIO因为xmodem多项式的特殊性并行度很高,1的数量才3个,只要获得索引只需要移位运算3次,像以太网的crc32就不行了,4通道才能并行4位,递推一下才8位,由于1的数量多,获得索引后还需要进行多次移位异或,软件上实现性能不太好。

 |手机版|深圳国芯人工智能有限公司
( 粤ICP备2022108929号-2 )
|手机版|深圳国芯人工智能有限公司
( 粤ICP备2022108929号-2 )
 发表于 2025-9-23 01:52:40
发表于 2025-9-23 01:52:40
 附件:main.c
附件:main.c%3Cbr/)

 发表于 2025-9-23 10:15:42
发表于 2025-9-23 10:15:42


